Decoupling Representation and Classifier for Long-Tailed Recognition
Decoupling Representation and Classifier for Long-Tailed RecognitionというICLR2020に採択された論文を紹介します.
Deep Learningのロングテールな不均衡データに対して,データのサンプリング戦略と,特徴抽出器と分類器の学習パターンによる違いを体系的に調査した論文です.
元の論文はこちら:
ロングテールな不均衡データ:
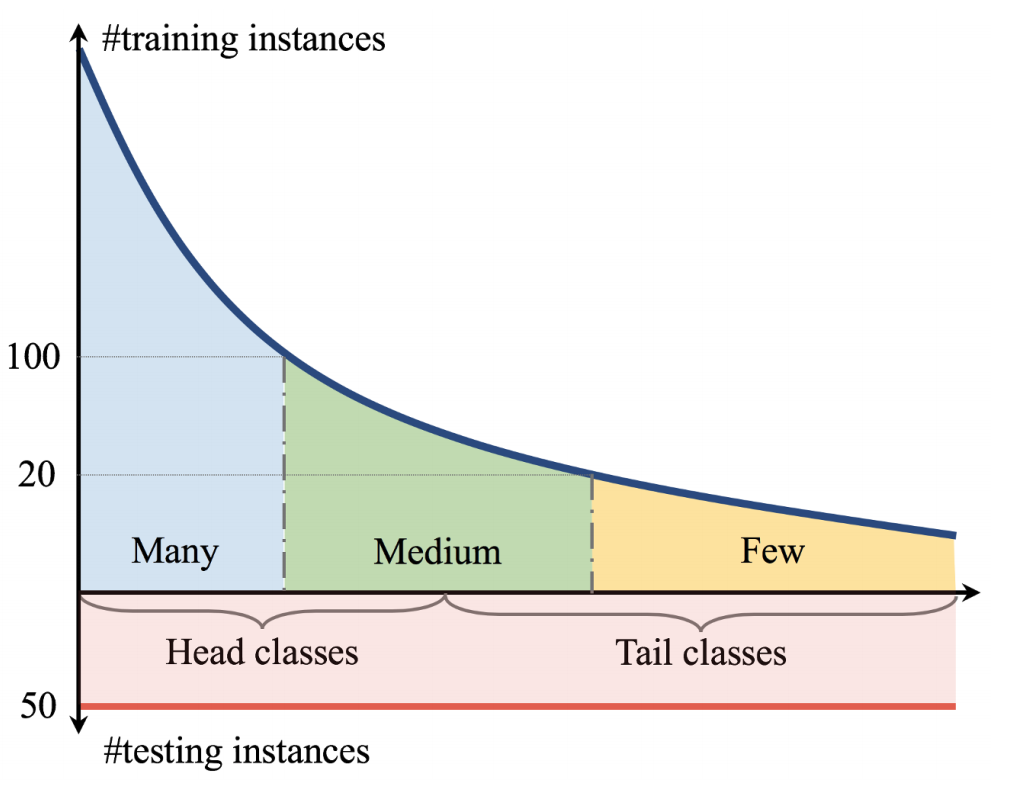
TL;DR
- ロングテールな不均衡データの分類タスクに対して,複数のデータサンプリング戦略と,特徴抽出器と分類器を同時に学習させたモデルと分類器のみ再学習したモデルを用いて比較実験.
- 不均衡データであることは,良い特徴抽出器の作成には問題にならないかもしれず,分類器の学習が重要.
- 不均衡データで学習したのち分類器のみ再学習したモデルの方が,クラス均衡サンプリングを適用した上で特徴抽出器と分類器を同時に学習したモデルよりも良い性能が得られる.
Abstract
クラス間のサンプル数に偏りがあるデータ「不均衡データ」の場合,サンプル数が少ないクラスに対するモデルの精度は低くなることが観測されています.この不均衡データに対する手法として,損失関数にクラスごとの重み付けをするLoss Re-Weightingや,データリサンプリング,サンプル数が多いクラスから少ないクラスへの転移学習などが提案されています.しかし,これらの手法は特徴抽出器と分類器の学習を同時に行っているため,特徴抽出器と分類器のどちらが効果的に働いているのかが明らかではないという課題があります.
上記の課題に取り組むため,この研究では,異なるデータサンプリング戦略のもとで,特徴抽出器と分類器を同時に学習する場合(Joint)と,同時に学習したのち分類器のみ再学習する場合(Decoupled)のモデルの精度を比較を通じて,これらの学習パターンものとでの特徴抽出器と分類器の効果を調査しています.
実験の結果,以下が観測されています.
- ロングテールな不均衡データに対しては,データサンプリングを工夫しない方が,最も汎化性の高い特徴抽出器が得られる.
- データサンプリングを工夫せず特徴抽出器を学習した後,分類器のみ再学習する際にクラス間均衡なデータサンプリングで学習する方が良好な性能が得られる.
- Decoupledで学習させた手法の方が,データサンプリングや損失関数を工夫した既存の手法よりも高い精度が達成できる.
Class-imbalanced dataに対する既存手法
サンプル数が少ないクラスに対するUnder Fittingを防ぐ観点から,ロングテールな不均衡データに対する様々な手法が提案されています. これらの手法は,大きく3つの手法に分類できます.
Data distribution re-balancing
クラス間のサンプル数のバランスをとるために,サンプル数が少ないクラスのデータをコピーして水増しするOversamplingや,逆にサンプル数が多いクラスのデータをサンプル数が少ないクラスのサンプル数まで減らすUndersamplingという手法があります.
Class-balanced Losses
各クラスのサンプル数に応じて異なる損失関数を適用する手法が提案されています.各クラスの出現確率に応じて損失関数に重み付けをするWeight Cross Entropy Lossや,クラスの確信度が高いクラスの損失関数値を小さくするようにスケーリングするFocal Lossなどが提案されています.
Transfer learning from head- to tail classes
サンプル数が多いクラスで学習した特徴量を用いて,サンプル数が少ないクラスの学習を行う方法が提案されています.
Learning Representation for Long-Tailed Recognition
これまで,ロングテールな不均衡データに対する手法が提案されてきましたが,前述の通り,特徴抽出器と分類器のどちらが効果的に働いているのか,については明らかではありませんでした. この論文では,複数のサンプリング戦略と学習パターンの組み合わせで実験を行い,特徴抽出器と分類器それぞれが持つ効果を調べています.
Sampling Strategies
各データサンプリング戦略において,クラスがサンプルされる確率を
とします.
は,全クラス数
,クラス
のデータ数
,サンプリング戦略ごとのパラメータ
]で表せます.
は,下記のサンプリング戦略ごとに
の値をとります.
Instance-balanced sampling
データサンプリングには工夫を加えず,不均衡データのまま使用.すなわち,各クラスは,そのクラスのデータ数に比例してサンプリングされる(サンプリング確率をとする).
.
Class-balanced sampling
各クラスのサンプルの出現確率を均等にする.すなわち,どのクラスも同じ確率でサンプリング.
.
Square-root sampling
各クラスのサンプルの出現確率に平方根を使用,.
Progressively-balanced sampling
上記のデータサンプリング戦略をミックスした手法.この論文では,学習の過程で,Instance-balanced samplingとClass-balanced samplingを同時に適用しながら,徐々にClass-balanced samplingの比重を高める方法を適用している.(:全エポック数,
:エポック)

Classification for Long-Tailed Recognition
複数のデータサンプリング戦略のほか,特徴抽出器と分類器を同時に学習するパターンと,特徴抽出器と分類器を分離した学習パターンを用意して,特徴抽出器と分類器の振る舞いを観察しています.
学習パターン
Jointly learning strategiesと複数のDecoupled learning stratediesで実験を行っています.
Jointly learning strategies
特徴抽出器と分類器を同時に学習する,一般的な学習手法です.
Decoupled learning stratedies
特徴抽出器と分類器を同時に学習したのち,分類器のみ再学習する手法です.Decoupledな学習についても複数の方法で実験を行っています.
Classifier Re-training (cRT)
分類器のみ再学習する際,Class-balanced samplingを適用.
Nearest Class Mean classifier (NCM)
学習データの各クラスの平均特徴量を計算し,コサイン類似度またはL2正則化で計算されたユークリッド距離を用いて最近傍探索を行う.
τ-normalized classifier (τ-normalized)
分類器の各クラスに紐づく重みのノルムで重みを正則化(はハイパーパラメータ)する方法.
(
はクラス
に紐づく重み)
τ-normalizationを適用後,モデルの出力はとなる.
Learnable weight scaling (LWS)
特徴抽出器の重みとτ-normalizationの重みを固定して,学習可能なscaling factor
のみ学習させる.
Experiments
前述したデータサンプリング戦略と学習パターンで,ImageNet-LTなどのデータセットと,ResNetやResNeXtのモデル実験を行っています.
実験の結果から,Jointly learning strategies(特徴抽出器と分類器を同時に学習)では,データサンプリング戦略が重要であり,Instance-balancedよりも他のデータサンプリング戦略の結果の方が良いことが観測されています.
JointlyとDecoupledの違いはどうでしょうか.Decoupledの方が全体的に良い性能を得られていることがわかります.さらに,Decoupledで学習する場合,データサンプリング戦略はInstance-balancedの時が最も良い性能を得られています.
この結果は,不均衡データは高い性能を持つ特徴抽出器の作成に当たってはそこまで問題にならないのではないか,ということを示唆しています.


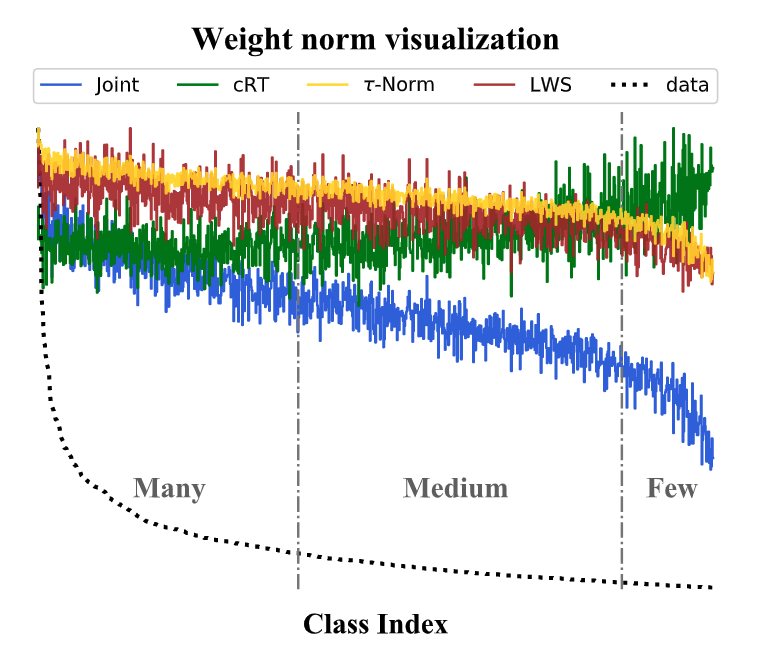
また,学習データの各クラスのサンプル数の分布と分類器の重みノルムのグラフから,Jointlyの場合は,クラスのデータ数が少なくなるに従って分類器の重みノルムが小さい,すなわちクラスのデータ数と分類器の重みノルムは正の相関関係にあることがわかります.
解説動画
Reference
- Kang, B., Xie, S., Rohrbach, M., Yan, Z., Gordo, A., Feng, J., and Kalantidis, Y. Decoupling representation and classifier for long-tailed recognition. ICLR, 2020.
JAIST社会人大学院進学を志してから合格まで
この4月から北陸先端科学技術大学院大学(JAIST)の博士前期課程(先端科学技術専攻)に進学します。社会人大学院生として情報科学の修士取得を目指します。
入学試験の対策に当たって、いろいろな方の受験体験記ブログに助けられました。私も、JAIST社会人大学院への進学を志してから合格に至るまでの記録を残しておこうと思います。この記事も今後JAISTを受験される方にとっての一助となれば幸いです。
www.jaist.ac.jp
背景
機械学習・深層学習スタートアップでエンジニア(3年目突入)をしています。前職までは経済学部⇨国家公務員なので、現職のエンジニアは未経験からのスタートです。
独学で学んでいたとはいえ、機械学習・深層学習はおろか、ソフトウェアエンジニアリングの基本の「き」の字もわかっていませんでした。正直よく入社させてもらったなと思います。それからは毎日ついていくことに必死でしたが、優秀な同僚に恵まれたおかげで、ここまでなんとかやってこれました。
(業務に慣れてきた今でも毎日必死です。このあたりは別で書きたいと思います。)
進学を志した理由
JAIST進学を志した理由は3点あります。
- コンピュータ・サイエンス(CS)を学びたい
- 指導教官の元で研究をしたい
- 情報科学の学位が欲しい
コンピュータ・サイエンス(CS)を学びたい
これまで体系的にCSを学んだことがないため、純粋にCSを学びたいと思いました。CSといっても、様々な言語やツールを使えるようになりたいというよりは(もちろん使えるようになりたいですが)、新しい技術や課題が出てきた時に、何を調べれば理解できるか、この技術はどの技術の応用か、この課題はどの手法なら解決できそうか、などの「当たりをつける」ための要素・基礎技術を学びたい考えています。
現在の業務では主に機械学習・深層学習のアルゴリズムを扱っていますが、表層的な理解しかできていない時も多々あります。課題に対してどの手法を適用すべきかがわからなかったり、新しい手法を理解するために何から手をつければ良いかわからず途方にくれてしまい、基礎力の足りなさをひしひしと感じます。こういう時に、どこから始めればよいか、がわかるインデックスとなる知見を持っているか否かで、対応速度に大きな違いが生じます。この「当たりをつける」ための基礎力を身につけることが、大学院での学びに期待していることです。
大学院2年間で受講できる講義は限られており、期待する項目を全て網羅できるわけではないですし、CSの基礎を学びたければ学部4年間の方が良いのではないかとも思います。ですが、私は、研究もしたかったことと、学部4年間は長いと感じたため、大学院への進学を選びました。
指導教官の元で研究がしたい
深層学習のためのGPU演算処理高速化について興味があり、これを研究を通じて学べたら自分の身になるのではないか、と考えたことがきっかけです。現在の業務の中で、メモリや演算速度を原因として深層学習モデルが実運用にのらないケースがあることを知り、いかにして既存のハードウェアでメモリ効率的または高速に演算を行うか、という課題を解くための専門性を持ちたいと考えるようになりました。
研究を通じて学ぶ、という思いが生まれたのは、個人で論文を国際会議にバンバン出している同僚から刺激を受けたことが大きいです。私の場合、学部の論文しか論文執筆経験がなく、研究したい分野の知見も多くないことから、一人で論文を執筆するのが困難であると感じたので、指導教官の方に相談できる環境に身をおきながら研究をしたいと考えました。
試験準備から試験結果発表までのスケジュール
JAISTの社会人コースの博士課程前期には、年間3回の試験があります。私は第1回の試験(2020年9月出願、10月試験)を受験しました。
試験は、出願時に提出する小論文と試験当日の面接で構成されています。試験当日は、小論文に基づいてプレゼン・質疑応答が行われます。
試験内容のメインは、小論文の内容「本学入学後に取り組みたい研究課題について」です。なので、研究テーマに関する調査が主な準備内容になります。
私の試験準備から試験結果発表までのおおまかなスケジュールです。
入学試験準備
入学試験に向けて、以下の準備をしました。
- 小論文の作成
- 発表用スライドの作成・発表練習
- 大学数学の復習
- 得意科目の復習
- 面接質疑応答 一問一答準備
※ その他、出願資料として、エントリーシートや職歴調書の作成があります。エントリーシートにはJAISTに進学するモチベーション、職歴調書にはこれまで経験とアピールポイントを記載します。
1. 小論文の作成
小論文は、エントリーシートや職歴調書と併せて出願時に提出するもので、公開されている所定の様式を使用して作成します。
小論文の課題は「本学入学後に取り組みたい研究課題について」です。A4サイズ1枚1,000字程度で、JAISTで取り組みたい研究内容について書きます。
私の場合、以下のような構成で作成しました。
- 研究の背景及び目的
- 世の中的になぜその研究が重要なのか、なぜその課題を解きたいのか、を記載しました。
- 先行研究とその課題
- 先行研究の概要と課題を記載しました。課題は複数の論文から共通して読み取れることや、論文のDiscussionパートで書かれている次の課題を参考にしながら、自分が取り組みたい内容を記載しました。
- 研究の方法
- 小論文の段階では、上記課題を解決するための具体的な手法案が思いつかなかったので、研究の手順を記載しました。具体的な手法案は、試験当日までになんとかしようと思い、とりあえず出願しました。
- 研究の遂行能力及び現状の課題
- これまでの経験から自分に研究する能力があること、研究を進めるに当たって自分に足りないこととNext Actionを記載しました。
研究したいテーマ決め
論文を5本くらい読んで決めました。研究内容をまとめるに当たっては合計15本くらい読みました。
注意したこと
その分野に詳しくない方でもわかるような文章を書くように注意しました。面接官の先生が必ずしもこの研究テーマに精通しているわけではないので、専門用語を使う場合は簡潔な説明をつけるようにしました。
反省点
研究方法の具体的な内容が書けなかったことです。聞き手が一番気になるのは研究方法なので、ここはできるだけ具体的にした方が良いです。
あと参考文献を書くべきなのですが、小論文の文字数が1,000字程度の中で参考文献を記載するとそれだけで文字数取られてしまうので小論文には記載しませんでした(発表資料の方では記載しました)。引用がある場合は、必ず記載すべきだと思います。
2. 発表用スライドの作成・発表練習
小論文を元に、試験当日の発表用のスライドを作成します。
発表時間の7分間で、ゆっくり話せる、かつ、スライド1枚あたりの情報量を抑えることを考え、スライド15枚(関連研究、参考文献除く)で作成しました。
スライドの目次
- 概要(目的、背景)
- 先行研究と課題
- 研究計画
- 関連研究
- 参考文献
発表用スライド
論文を書きまくってる同僚の強強リサーチエンジニアの方や、私のプログラミングの師匠と呼べる方、友人に発表練習に付き合ってもらい、コメントをもらいました。指摘を受けてからやったことで特によかったのが、「取り組みたいこと」「既存研究の問題点」「研究のアプローチ」の3点を書いたスライド1枚を発表資料の最初と最後に挿入したことです。これのおかげで、「最悪7分間におさまらなくても言いたいことは伝わっているはず」と焦らずに発表できました。
まだまだ研究テーマもアプローチも穴だらけで、科学的にも私の実力的にも上手くいくか自信はないですが、研究室の先生のアドバイスをいただきながら進めていきたいです。
3. 大学数学の復習
微分積分・線形代数をマセマ本*2*3を使って復習していました。いざ面接の場で問われた時に答えられる自信がなかったので、範囲を絞って簡単にノートにまとめていました。
面接で聞かれることはなかったのですが、大学院の授業を受ける上で最低限必要となる知識なので、復習をしておいて損はないはずです。
4. 得意科目の復習
大学時代の講義ノートや教科書を押入れから引っ張り出して、聞かれた時に話す内容をまとめました。入学試験当日は聞かれなかったのですが、大学時代の学びを思い出す良い機会となりました。
5. 面接質疑応答 一問一答準備
心配性なので、面接対策用に一問一答を準備していました。
一問一答の内容例
- この研究の新規性は?
- モデルとデータセットは何使う予定?
- 使用するモデルの特徴はなに?
- 〇〇(研究分野の専門用語)の定義を説明して
- アプローチはどこで思いついたの?
- なぜこれを研究対象に選んだの?
- 線形代数の固有値・固有ベクトル説明して
- 履修してみたい講義は?
なお、履修したい講義については、出願前にまとめていました。会社の技術顧問の先生に教えてもらった方法で、縦軸:重要度、横軸:面白さの2軸の図で講義を整理していました。

私は心配性なので、まだ準備が足りない、他のブログ書いている人はもっとすごい人、自分は練習しないとダメな人...と、必死でした。準備をすればするほどわからないことが明らかになっていくので、どれだけ準備しても不安は消えませんでした。
前日にようやく、ここまできたらどんな結果でもいいや、と半分吹っ切れた気持ちに切り替えることができ、試験当日を迎えました。
入試当日
コロナの状況のため、オンラインでの面接となりました。
面接の流れ
- プレゼンテーション資料を画面共有をしながら発表(7分間)
- 面接官の先生方から質疑応答(23分間)
やりとりの詳細は記載できないですが、私の場合は、プレゼンテーションと小論文の内容についての質疑応答が主で、研究内容以外はあまり聞かれませんでした。ですが、過去には、学部時代の得意科目についての説明や、線形代数の固有値・固有ベクトルの説明を求められた方もいたようです。
質問にもほどよく回答できたので、面接が終わった後の感触はやり切ったという感じでした。
発表練習を同僚・友人に付き合ってもらったおかげで当日落ち着いて発表できました。事前に誰かに聞いてもらうことは大事と改めて感じました。協力いただいた方々には本当に感謝感謝です。
結果発表
10月31日に速達で届き、無事に合格していました。
これから
合格の喜びも束の間、不安が押し寄せてきました。JAIST社会人の先輩方のブログやTwitterをみていると、みなさん血反吐を吐きながら取り組まれているようです。私も講義についていけるかとても不安です。
正直、自分にとってJAISTへの進学が正解なのかはわからないです。大学院は大変で血反吐を吐く、CS学ぶなら学部からでしょ、大学院では直接業務で生かせることは学べないのでは、といった声もあるので、本当に進学すべきだろうか、という迷いはあります。
とはいえ、JAISTには長期履修制度(追加の学費なしで入学から修了までの期間を2年から3年まで延長できる制度)があったり、現職の会社のサポート(研究日1日の確保、学費一部支給)もあるので、まずは頑張っていこうと思います。授業もどれもとても面白そうで取りたくなるものばかりで、ワクワクしています。このワクワク感を大切に、2年間(ないし3年間)楽しんで過ごそうと思います。
*1:研究室訪問では、研究したい内容の資料を見せながら、研究室でやりたいことができるかを確認したり、先生から研究室の紹介をしてもらいました。