Decoupling Representation and Classifier for Long-Tailed Recognition
Decoupling Representation and Classifier for Long-Tailed RecognitionというICLR2020に採択された論文を紹介します.
Deep Learningのロングテールな不均衡データに対して,データのサンプリング戦略と,特徴抽出器と分類器の学習パターンによる違いを体系的に調査した論文です.
元の論文はこちら:
ロングテールな不均衡データ:
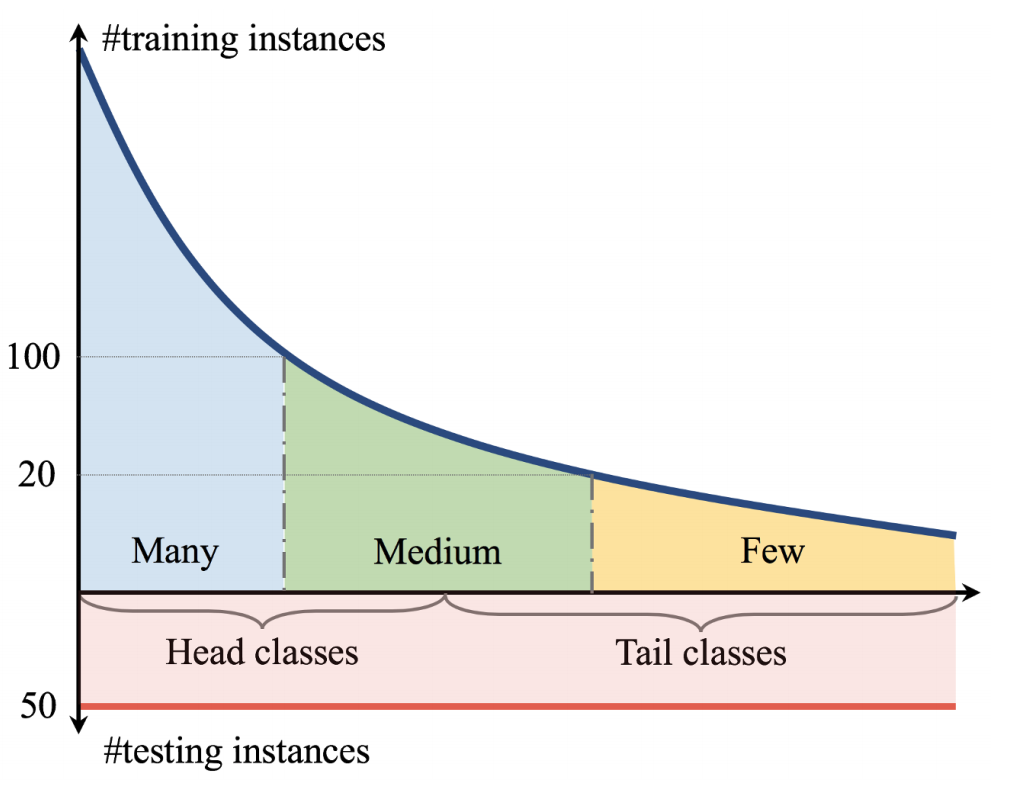
TL;DR
- ロングテールな不均衡データの分類タスクに対して,複数のデータサンプリング戦略と,特徴抽出器と分類器を同時に学習させたモデルと分類器のみ再学習したモデルを用いて比較実験.
- 不均衡データであることは,良い特徴抽出器の作成には問題にならないかもしれず,分類器の学習が重要.
- 不均衡データで学習したのち分類器のみ再学習したモデルの方が,クラス均衡サンプリングを適用した上で特徴抽出器と分類器を同時に学習したモデルよりも良い性能が得られる.
Abstract
クラス間のサンプル数に偏りがあるデータ「不均衡データ」の場合,サンプル数が少ないクラスに対するモデルの精度は低くなることが観測されています.この不均衡データに対する手法として,損失関数にクラスごとの重み付けをするLoss Re-Weightingや,データリサンプリング,サンプル数が多いクラスから少ないクラスへの転移学習などが提案されています.しかし,これらの手法は特徴抽出器と分類器の学習を同時に行っているため,特徴抽出器と分類器のどちらが効果的に働いているのかが明らかではないという課題があります.
上記の課題に取り組むため,この研究では,異なるデータサンプリング戦略のもとで,特徴抽出器と分類器を同時に学習する場合(Joint)と,同時に学習したのち分類器のみ再学習する場合(Decoupled)のモデルの精度を比較を通じて,これらの学習パターンものとでの特徴抽出器と分類器の効果を調査しています.
実験の結果,以下が観測されています.
- ロングテールな不均衡データに対しては,データサンプリングを工夫しない方が,最も汎化性の高い特徴抽出器が得られる.
- データサンプリングを工夫せず特徴抽出器を学習した後,分類器のみ再学習する際にクラス間均衡なデータサンプリングで学習する方が良好な性能が得られる.
- Decoupledで学習させた手法の方が,データサンプリングや損失関数を工夫した既存の手法よりも高い精度が達成できる.
Class-imbalanced dataに対する既存手法
サンプル数が少ないクラスに対するUnder Fittingを防ぐ観点から,ロングテールな不均衡データに対する様々な手法が提案されています. これらの手法は,大きく3つの手法に分類できます.
Data distribution re-balancing
クラス間のサンプル数のバランスをとるために,サンプル数が少ないクラスのデータをコピーして水増しするOversamplingや,逆にサンプル数が多いクラスのデータをサンプル数が少ないクラスのサンプル数まで減らすUndersamplingという手法があります.
Class-balanced Losses
各クラスのサンプル数に応じて異なる損失関数を適用する手法が提案されています.各クラスの出現確率に応じて損失関数に重み付けをするWeight Cross Entropy Lossや,クラスの確信度が高いクラスの損失関数値を小さくするようにスケーリングするFocal Lossなどが提案されています.
Transfer learning from head- to tail classes
サンプル数が多いクラスで学習した特徴量を用いて,サンプル数が少ないクラスの学習を行う方法が提案されています.
Learning Representation for Long-Tailed Recognition
これまで,ロングテールな不均衡データに対する手法が提案されてきましたが,前述の通り,特徴抽出器と分類器のどちらが効果的に働いているのか,については明らかではありませんでした. この論文では,複数のサンプリング戦略と学習パターンの組み合わせで実験を行い,特徴抽出器と分類器それぞれが持つ効果を調べています.
Sampling Strategies
各データサンプリング戦略において,クラスがサンプルされる確率を
とします.
は,全クラス数
,クラス
のデータ数
,サンプリング戦略ごとのパラメータ
]で表せます.
は,下記のサンプリング戦略ごとに
の値をとります.
Instance-balanced sampling
データサンプリングには工夫を加えず,不均衡データのまま使用.すなわち,各クラスは,そのクラスのデータ数に比例してサンプリングされる(サンプリング確率をとする).
.
Class-balanced sampling
各クラスのサンプルの出現確率を均等にする.すなわち,どのクラスも同じ確率でサンプリング.
.
Square-root sampling
各クラスのサンプルの出現確率に平方根を使用,.
Progressively-balanced sampling
上記のデータサンプリング戦略をミックスした手法.この論文では,学習の過程で,Instance-balanced samplingとClass-balanced samplingを同時に適用しながら,徐々にClass-balanced samplingの比重を高める方法を適用している.(:全エポック数,
:エポック)

Classification for Long-Tailed Recognition
複数のデータサンプリング戦略のほか,特徴抽出器と分類器を同時に学習するパターンと,特徴抽出器と分類器を分離した学習パターンを用意して,特徴抽出器と分類器の振る舞いを観察しています.
学習パターン
Jointly learning strategiesと複数のDecoupled learning stratediesで実験を行っています.
Jointly learning strategies
特徴抽出器と分類器を同時に学習する,一般的な学習手法です.
Decoupled learning stratedies
特徴抽出器と分類器を同時に学習したのち,分類器のみ再学習する手法です.Decoupledな学習についても複数の方法で実験を行っています.
Classifier Re-training (cRT)
分類器のみ再学習する際,Class-balanced samplingを適用.
Nearest Class Mean classifier (NCM)
学習データの各クラスの平均特徴量を計算し,コサイン類似度またはL2正則化で計算されたユークリッド距離を用いて最近傍探索を行う.
τ-normalized classifier (τ-normalized)
分類器の各クラスに紐づく重みのノルムで重みを正則化(はハイパーパラメータ)する方法.
(
はクラス
に紐づく重み)
τ-normalizationを適用後,モデルの出力はとなる.
Learnable weight scaling (LWS)
特徴抽出器の重みとτ-normalizationの重みを固定して,学習可能なscaling factor
のみ学習させる.
Experiments
前述したデータサンプリング戦略と学習パターンで,ImageNet-LTなどのデータセットと,ResNetやResNeXtのモデル実験を行っています.
実験の結果から,Jointly learning strategies(特徴抽出器と分類器を同時に学習)では,データサンプリング戦略が重要であり,Instance-balancedよりも他のデータサンプリング戦略の結果の方が良いことが観測されています.
JointlyとDecoupledの違いはどうでしょうか.Decoupledの方が全体的に良い性能を得られていることがわかります.さらに,Decoupledで学習する場合,データサンプリング戦略はInstance-balancedの時が最も良い性能を得られています.
この結果は,不均衡データは高い性能を持つ特徴抽出器の作成に当たってはそこまで問題にならないのではないか,ということを示唆しています.


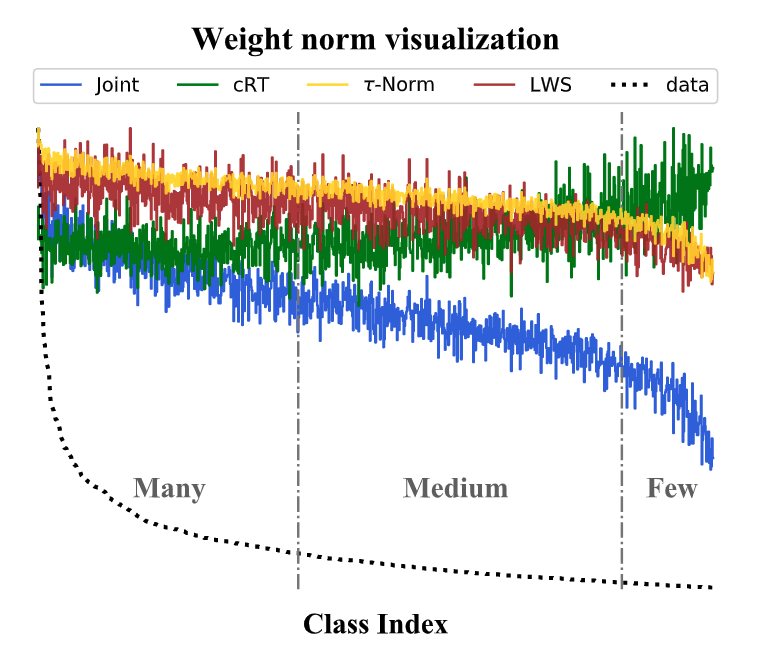
また,学習データの各クラスのサンプル数の分布と分類器の重みノルムのグラフから,Jointlyの場合は,クラスのデータ数が少なくなるに従って分類器の重みノルムが小さい,すなわちクラスのデータ数と分類器の重みノルムは正の相関関係にあることがわかります.
解説動画
Reference
- Kang, B., Xie, S., Rohrbach, M., Yan, Z., Gordo, A., Feng, J., and Kalantidis, Y. Decoupling representation and classifier for long-tailed recognition. ICLR, 2020.